
About customer:
Torrent Pharma, the flagship Company of Torrent Group, with a turnover of Rs. 8005 Cr is one of the leading Pharma companies in the Country. We are the pioneers in initiating the concept of niche marketing in India and today is ranked amongst the leaders in the therapeutic segment of cardiovascular (CV), central nervous system (CNS), gastro-intestinal (GI) and women healthcare (WHC). The Company also has significant presence in diabetology, pain management, gynaecology, oncology and anti-infective segments.
Torrent Pharma has crossed many geographical boundaries with presence in more than 40 countries. The Company is ranked first amongst Indian Companies for having largest market share in Brazil and Germany.
Challenges:
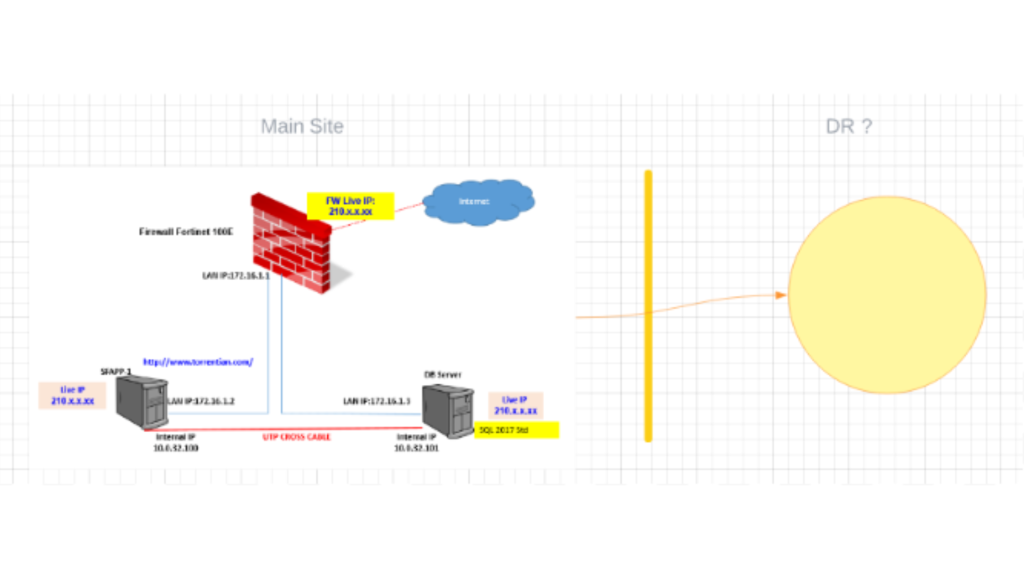
Sales Force automation Application and Database servers are installed/Collocated at ATMA House Ashram Road Ahmedabad Sify Data center. And more than 7000 field staff are accessing this application over the internet. Below is the schematic diagram/ Existing Server configuration.
It is one of the most important applications that should have DR, can not tolerate downtime which leads to heavy financial losses and equally bad effect on company reputation.
Why AWS?
GTU determined that a public cloud service platform could deliver the needed and provide embedded solutions to their problems. As Amazon connect is a low-cost service and omni-channel cloud solution for IT helpdesk, admissions and other departments needing to provide inbound and outbound support.
Why Ingways?
To create a customized infrastructure that is more flexible and easier to use to scale up on-premises applications by migrating them to cloud when your server needs are low. Ingways has demonstrated success in providing specialized solutions aligning with AWS architectural best practices to help support teaching and learning, administration, and academic research efforts in education.
Partner Solution
Solution Architecture is proposed with CloudEndure based Disaster Recovery Solution. CloudEndure is an AWS product used for Disaster Recovery and also Cloud Migrations. Both solutions are powered by CloudEndure’s innovative workload mobility technology, which continuously replicates applications from physical, virtual, or cloud-based infrastructure to a low-cost “staging area” (as detailed in Solution Architecture) that is automatically provisioned in any target AWS Region Mumbai. During failover, cutover, or testing, an up-to-date copy of applications can be spun up on demand and be fully functioning in minutes. It enables sub-second Recovery Point Objectives (RPOs) and Recovery Time Objectives (RTOs) of minutes.
a. Initial Setup
Step 1: Setup CloudEndure Account and Project. This is a onetime step where by customer’s CloudEndure account is setup with registering for Disaster Recovery. Once signed in, new Project need to be created in CloudEndure “User Console”.
Step 2: Define Replication settings and Target Cloud environment Blueprint. Before we start replicating the machines, we need to define replication settings and blueprint under the newly setup project. Here, you define your Source (2 servers) and Target environments, and the default Replication Servers in the Staging Area of the Target infrastructure.
Step 3 : Network configuration at either side to be configured with source public IP and cloud allocated EIP (Elastic IP) so that even over the Internet traffic is allowed only by whitelisted IPs. CloudEndure shall by default encrypt all traffic between on premise and AWS cloud
Step 4: Add machines by installing the CloudEndure Agent on each source machines. Agents can be installed on both Linux and Windows machines. Detailed instructions can be referred here. CloudEndure does not require separate physical / virtual machine for setting up sync between on-premises and cloud server.
Step 5: Once agents are installed and setup under CloudEndure “UserConsole”, these machines shall start replicating initial full data transfer. It shall take hours to days to complete initial replication depending upon internet bandwidth between on premise and AWS Cloud. Once initial sync is completed, CloudEndure only syncs incremental changed block data storage. CloudEndure also compresses data and optimize outgoing internet bandwidth and cost.
b. Disaster Event / Drill
Step 1: Go to CloudEndure Console and under “Launch Target”, you can initiate “Test Mode” for DR Drill and “Recovery Mode” for actual Disaster Event. Under “Test Mode” replication between on premise and AWS Cloud, is not interrupted.
Step 2: CloudEndure takes regular snapshots on cloud to support “Point in time” recovery. This is very useful in case of Ransomware / data corruption at source which also would have impacted cloud synced data. During “Launch Target” you can choose respective snapshot which you would like the respective machine to use (default will be the latest snapshot with recently synced data).
Step 3: After Target instances are launched (within minutes), please verify each launched instance through Remote Desktop (RDP). Here, newly launched DB machine can be accessed through Application Server.
Step 4: Assuming cloud public IP (EIP) is already configured as failover IP in DNS configuration, you can verify the application should be up and running under same domain URL.
c. Failback post Disaster
In a Disaster Event scenario, once on premise infrastructure is recovered, you can perform failback steps to sync in reverse order to get your original infrastructure in data sync state.
Step 1: Under CloudEndure Console, Click on the “Project Actions” menu and select “Prepare for Failback”. Project will go into Preparing for failback to original Source status.
Step 2: CloudEndure needs a Failback client to be installed and configured to boot from the original source machine to start reverse sync from AWS Cloud to respective on premise servers. Failback Client (failback_client.iso) can be downloaded from the Replication Settings section in the CloudEndure User Console under Setup & Info.
Step 3: Once all machines are recovered at on premise location, perform complete verification steps and route application traffic through DNS.
Step 4: Go to CloudEndure console under “Project Actions” and click “Return to Normal Operation”, this will again start the normal replication process which was going on before initiating the Disaster event.
Step 5: Delete Target Machines used during Disaster Recovery by going to CloudEndure console and under “Machine Actions” click “Delete Target Machines.
Results and Benefits
The Recovery Point Objective (RPO) of CloudEndure is typically in the sub-second range. Near real time RPO is achieved and tested by customer successfully.
The Recovery Time Objective (RTO) of CloudEndure is typically measured in minutes. The RTO is highly dependent on the OS boot time. As per the client requirement it was achieved and converted to automation for speedy recovery at the time of DR.
CloudEndure is very secure for data in transit and data at rest, in both the cases it is encrypted. CloudEndure stores only configuration and log data on the CloudEndure Service Manager’s encrypted database. Replicated data is always stored on the customer’s own cloud VPC. The replicated data is encrypted in transit.
CloudEndure supports one of the most important features and it is the customer needs. The feature is called Point-in-Time Recovery snapshots. Point-In-Time Recovery snapshots was configured from the following schedule:
every 10 minutes in the past hour
every 1 hour in the past 24 hours
every 1 day in the past 30 days
With cloudEndure customers saved lots of time to set up, maintain and monitor DR.
Cost reduction due to no actual machines being running it will only run at the time of DR drill.
No cost and time for training and as such a solution is delivered, maintained and troubleshooted by a partner backed by AWS Premium support.
Very simple, transparent and effective solution with the best of TCO.
Next Steps
With the successful achievement of DR, customer is not just looking for DR of other important applications, but planning other production workloads to be moved to the cloud in near future.